
 Voici un petit problème qui se présente assez fréquemment sous diverses formes, et pour lequel j’ai été surpris de ne pas trouver de solution bien documentée.
Voici un petit problème qui se présente assez fréquemment sous diverses formes, et pour lequel j’ai été surpris de ne pas trouver de solution bien documentée.
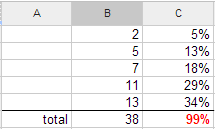
Le cas le plus simple apparaît souvent dans les tableurs : en calculant des pourcentages arrondis, le total ne fait parfois pas 100%. En effet, rien ne garantit que les arrondis « vers le haut » compensent ceux « vers le bas ». Autrement dit, une somme d’arrondis n’est pas égale à la somme arrondie.
Autre exemple assez différent en apparence. Un berger veut répartir ses 1548 moutons sur sa parcelle carrée d’un hectare où il veut faire paître a moutons, son parc rond de π hectares qui peut en accueillir b, et les c restants sur la parcelle louée à son voisin le père Néper, qui fait e hectares, de manière à ce que chaque mouton ait la même surface à brouter. Sur les conseils de l’instituteur du village, il commence par écrire la petite équation a.(1+π+e) = 1548 pour obtenir a = 225.66 puis b=708.93 et c=613.41, mais ensuite, comment arrondir chacun de ces nombres vers le haut ou le bas de façon à obtenir exactement un total de 1548 et que les rapports b/a et c/a restent respectivement proches de π et de e ?
C’est en planchant sur un problème de ce type que m’est venue une idée : utiliser une méthode du scrutin proportionnel plurinominal !
Certains parlements comme le Conseil National (Suisse) sont élus à la « proportionnelle par liste » : le nombre de sièges étant fixé, on commence par répartir ces sièges entre les partis proportionnellement aux nombre de listes portant l’entête d’un parti choisies par les électeurs. Dans une deuxième phase, les n candidats ayant reçu le plus de voix de chaque parti sont élus aux n sièges attribués à leur parti, mais ceci n’est pas le sujet ici.
La phase de répartition des sièges entre partis rencontre exactement les difficultés liées aux arrondis mentionnées plus haut, et comme l’enjeu est d’importance politique, le problème a été non seulement étudié depuis longtemps, mais les solutions sont mêmes formalisées dans les lois régissant le système électoral de bon nombre d’Etats (voir [1] par exemple). Le hic, c’est qu’il n’y a pas une seule solution définitive mais plusieurs, chacune avec ses avantages et inconvénients.

q = (1+π+e)/1548 = 0.004431 , ce qui n’est autre que la surface à brouter par chaque mouton.
Puis on effectue la division euclidienne (ou entière) du nombre de votes obtenus par chaque parti par ce nombre q. Peu importe que dans notre cas, les votes soient remplacés par des nombres réels, l’important est que l’on souhaite diviser un nombre entier en entiers suivant cette proportion.
On commence par ne considérer que les quotients des divisions entières (notées // en Python) et assigner
a = 1//q = 225, b = π//q = 708 et c = e//q = 613 moutons aux trois champs. Mais a+b+c ne totalisant que 1546 moutons, il reste à attribuer les moutons restants aux deux « plus fort restes » des divisions entières. Dans notre cas, 1-a.q = 0.0029, π-b.q = 0.0041 et e-c.q = 0.0018, donc on alloue un mouton de plus aux champs b et a pour obtenir finalement a=226, b=709 et c=613.
La méthode de Hare souffre d’un défaut appelé paradoxe de l’Alabama : le fait d’augmenter de 1 le nombre de sièges/moutons peut dans certains cas faire diminuer de 1 le nombre alloué à l’un des partis/prés, ce qui est illogique. De plus, la méthode de Hare avantage les petits partis qui pourraient gagner leur seul élu au plus fort reste. Les grands partis pourraient même être tentés de déposer plusieurs listes apparentées pour gagner des sièges, c’est pourquoi les législations introduisent souvent un quorum ou « seuil de représentativité » sous la forme d’un pourcentage minimum de votes à atteindre pour qu’une liste soit prise en considération*.
On peut diminuer la probabilité d’apparition de ces défauts à l’aide d’une astuce due à Eduard Hagenbach-Bischoff (1833-1910), scientifique suisse qui proposa de calculer le « quotient électoral » en divisant le nombre total de votes valides par le nombre de sièges à pourvoir augmenté de 1. Le « quotient de Hagenbach-Bischoff » vaut dans notre cas q = (1+π+e)/(1548+1) = 0.004429. La différence par rapport à la méthode de Hare est très faible, mais suffit à répartir 225+709+613=1547 moutons du premier coup, n’en laissant qu’un à attribuer au parti/pré a puisqu’il présente le reste de division le plus élevé, ce qui nous donne le même résultat qu’Hare dans ce cas précis : a=226, b=709 et c=613

Mais revenons à nos moutons : la méthode Hare suffit parfaitement à mon problème, mais le quotient de Hagenbach-Bischoff ajoute un petit plus de science helvétique qui me plaît assez…
J’ai donc codé la méthode du plus fort reste dans un tableur Google exportable en Excel. Trois onglets résolvent le cas des 1548 moutons, celui des pourcentages du début de l’article, et celui du scrutin proportionnel utilisé comme exemple dans la page Wikipédia et qui donne des résultats différents selon le quotient électoral ( Hare, Hagenbach-Bischoff ou Imperiali) choisi. Pour les curieux, la cellule F1 utilise la fonction Excel LARGE, GRANDE.VALEUR en français pour obtenir la n-ième plus grande valeur des restes calculés dans la colonne E, où n est le nombre de sièges restant à attribuer. Ensuite un simple test permet de déterminer dans la colonne F si un siège/mouton/pourcent doit être ajouté.
Le « bug connu », c’est qu’en cas d’égalité des restes il se pourrait qu’on en ajoute trop, mais je ne sais pas trop comment empêcher ceci en Excel sans macro… Par contre ce problème est évité dans la fonction Python que j’ai réalisée pour mon application:
Si vous trouvez ce code utile ou intéressant, vous pouvez voter pour ma réponse à une question sur StackOverflow, ça me fera une voix de plus en attendant un siège …
Note : * à mon humble avis le quorum devrait donc être approximativement égal à 1 / le nombre de sièges à pourvoir, donc autour de 1% plutôt que 5 ou 7% dans certains parlements…
Références:
- « Loi fédérale sur les droits politiques, Art 40«
- David Madore « Élections à la proportionnelle : illustrations« , 10 juin 2009



{kind=link}
8 commentaires sur “Répartition proportionnelle”
Si vous êtes intéressé par le sujet je vous conseille le livre de Michel Balinski « Le suffrage universel inachevé » où il expliquent les propriétés (et parfois défauts) des méthodes de répartitions.
Merci, j’ai ajouté https://www.goodreads.com/book/show/35144491-le-suffrage-universel-inachev à ma liste des livres à lire un jour… Dans cet article je ne m’intéresse qu’au problème numérique de la répartition (sur lequel il y a certainement encore beaucoup à dire, cf commentaires ci-dessous). Sur les systèmes de vote j’avais écrit ça https://drgoulu.com/2007/05/09/le-vote-par-assentiment/ , avec mention de Balinski dans les commentaires.
Découvert l’indice de Gallagher ( https://fr.wikipedia.org/wiki/Indice_de_Gallagher ) grâce à un buzz canadien http://www.huffingtonpost.ca/2016/12/01/maryam-monsef-math-equation-electoral-reform_n_13358776.html . je vais l’intégrer à la feuille de calcul…
La figure sur https://napoleonsnightmare.ch/tag/gallagher-index-of-disproportionality/ est intéressante:
https://napoleonsnightmare.files.wordpress.com/2015/12/gallagher-kr-wahlen-2012-2015.png
Elle montre les disparités de la proportionnalité entre Cantons suisses, liée à leur taille et apparemment aussi aux système électoraux. La toute nouvelle répartition biproportionnelle est-elle vraiment meilleure ?
J’ai ajouté l’indice de Ghallager à ma feuille de calcul https://docs.google.com/spreadsheets/d/1vpcUqQkzEWagPf5DpvoiMdqr3qyRQ-TIRW4cLKUlUos/edit?usp=sharing
En replongeant dans le sujet « double proportionnelle » de Pukelsheim, je tombe sur https://www.math.uni-augsburg.de/htdocs/emeriti/pukelsheim/bazi/ avec une importante bibliographie ici https://www.math.uni-augsburg.de/htdocs/emeriti/pukelsheim/bazi/literature.html et de https://en.wikipedia.org/wiki/Iterative_proportional_fitting vers une librairie Python https://github.com/Dirguis/ipfn
Bonjour,
A propos du « bug connu », je me permets de vous soumettre une solution avec excel, sans macro, qui tire parti une propriété (non prévue?) intéressante de la fonction ABS qui est que ABS(plage de cellule) a le format d’une plage de cellule.
On peut par exemple faire SOMMEPROD(ABS($E$2:$E$19>=E2)) qui permet de compter les valeurs de la plage supérieures a la valeur E2.
En jouant un peu avec les plages fixes et variables on peut écrire la formule suivante :
SOMMEPROD(ABS($E$2:$E$19>=E2))-SOMMEPROD(ABS($E2:$E$19>=E2))+1 (notez que le deuxième E2 n’est pas fixé en ligne)
L’idée est de:
– compter le nombre de cellules dans la colonne E dont la valeur est supérieure ou égale à la valeur de la cellule en cours
– retrancher le nombre de cellules dans la colonne E, situées en dessous de la cellule en cours, dont la valeur est supérieure ou égale à la valeur de la cellule en cours
Cela permet d’associer chaque valeur du tableau à un ordre strictement croissant
Malheureusement, la fonction ABS ne semble pas avoir les mêmes propriétés avec Google Drive, le résulta n’apparaîtra par conséquent pas directement ici :
https://docs.google.com/spreadsheet/ccc?key=0Au-xkr1zIB2OdHI0b3JnSkwtUXZhTG5DRWJVb3I2N2c&usp=sharing
Mais il apparaîtra si le fichier est exporté localement au format excel pour que la formule s’active correctement.
Ou en réutilisant la formule ci-dessus dans excel.
Excellent! je me suis aussi souvent demander comment mettre des répartitions en entier sans tomber dans des -1; +1 par rapport au total. Il serait intéressant de savoir si il y a des applications dans la réduction d’échantillonnage ou de résolution d’image.